分析训练完成的机器学习模型的性能是任何机器学习工作流程中必不可少的步骤。 在PyCaret中分析模型性能就像编写plot_model一样简单。 该函数将受训的模型对象和图的类型作为plot_model函数中的字符串。
分类:
| Name | Plot |
| Area Under the Curve | ‘auc’ |
| Discrimination Threshold | ‘threshold’ |
| Precision Recall Curve | ‘pr’ |
| Confusion Matrix | ‘confusion_matrix’ |
| Class Prediction Error | ‘error’ |
| Classification Report | ‘class_report’ |
| Decision Boundary | ‘boundary’ |
| Recursive Feature Selection | ‘rfe’ |
| Learning Curve | ‘learning’ |
| Manifold Learning | ‘manifold’ |
| Calibration Curve | ‘calibration’ |
| Validation Curve | ‘vc’ |
| Dimension Learning | ‘dimension’ |
| Feature Importance | ‘feature’ |
| Model Hyperparameter | ‘parameter’ |
例子:
# Importing dataset
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# creating a model
lr = create_model('lr')
# plotting a model
plot_model(lr)
![]()
![]()
回归:
| Name | Plot |
| Residuals Plot | ‘residuals’ |
| Prediction Error Plot | ‘error’ |
| Cooks Distance Plot | ‘cooks’ |
| Recursive Feature Selection | ‘rfe’ |
| Learning Curve | ‘learning’ |
| Validation Curve | ‘vc’ |
| Manifold Learning | ‘manifold’ |
| Feature Importance | ‘feature’ |
| Model Hyperparameter | ‘parameter’ |
例子:
# Importing dataset
from pycaret.datasets import get_data
boston = get_data('boston')
# Importing module and initializing setup
from pycaret.regression import *
reg1 = setup(data = boston, target = 'medv')
# creating a model
lr = create_model('lr')
# plotting a model
plot_model(lr)
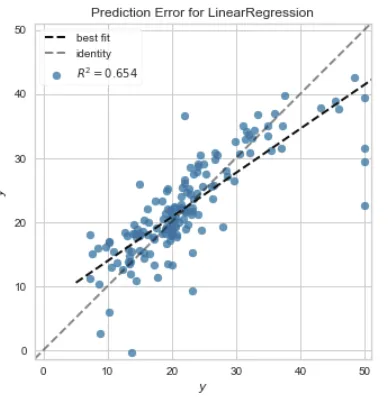

聚类:
| Name | Plot |
| Cluster PCA Plot (2d) | ‘cluster’ |
| Cluster TSnE (3d) | ‘tsne’ |
| Elbow Plot | ‘elbow’ |
| Silhouette Plot | ‘silhouette’ |
| Distance Plot | ‘distance’ |
| Distribution Plot | ‘distribution’ |
例子:
# Importing dataset
from pycaret.datasets import get_data
jewellery = get_data('jewellery')
# Importing module and initializing setup
from pycaret.clustering import *
clu1 = setup(data = jewellery)
# creating a model
kmeans = create_model('kmeans')
# plotting a model
plot_model(kmeans)
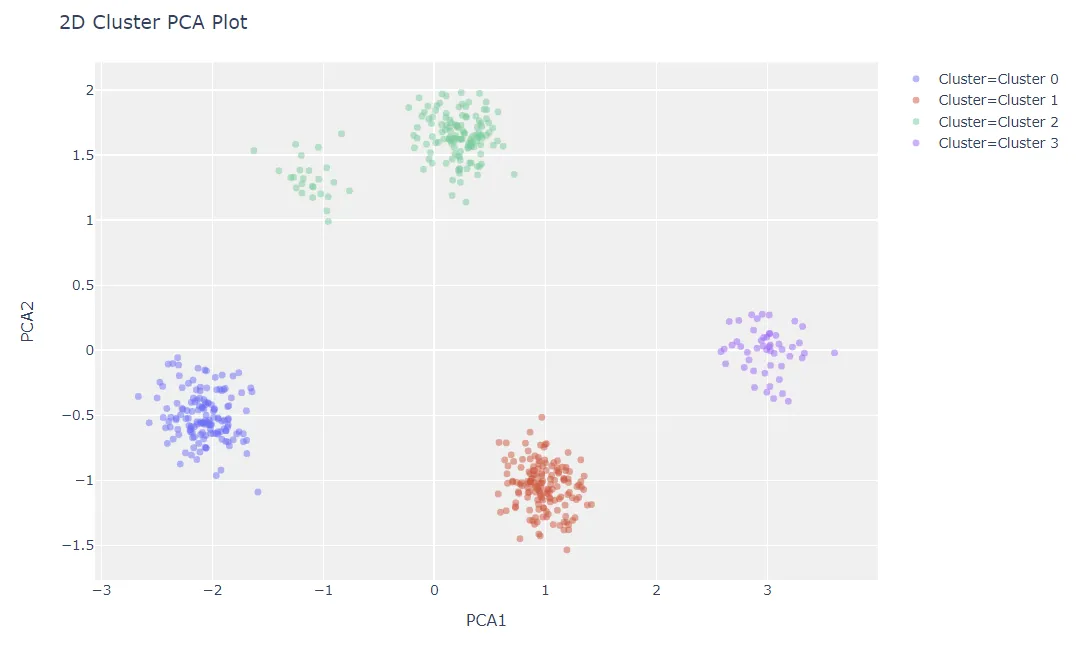

异常检测:
| Name | Plot |
| t-SNE (3d) Dimension Plot | ‘tsne’ |
| UMAP Dimensionality Plot | ‘umap’ |
例子:
# Importing dataset
from pycaret.datasets import get_data
anomalies = get_data('anomaly')
# Importing module and initializing setup
from pycaret.anomaly import *
ano1 = setup(data = anomalies)
# creating a model
iforest = create_model('iforest')
# plotting a model
plot_model(iforest)
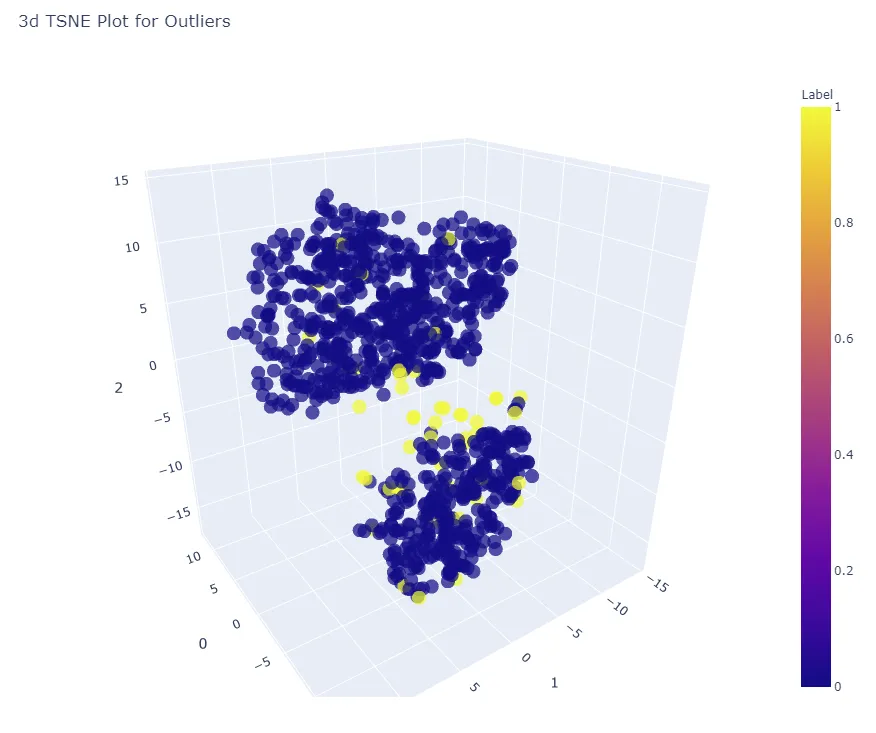

自然语言处理:
| Name | Plot |
| Word Token Frequency | ‘frequency’ |
| Word Distribution Plot | ‘distribution’ |
| Bigram Frequency Plot | ‘bigram’ |
| Trigram Frequency Plot | ‘trigram’ |
| Sentiment Polarity Plot | ‘sentiment’ |
| Part of Speech Frequency | ‘pos’ |
| t-SNE (3d) Dimension Plot | ‘tsne’ |
| Topic Model (pyLDAvis) | ‘topic_model’ |
| Topic Infer Distribution | ‘topic_distribution’ |
| Word cloud | ‘wordcloud’ |
| UMAP Dimensionality Plot | ‘umap’ |
例子:
# Importing dataset
from pycaret.datasets import get_data
kiva = get_data('kiva')
# Importing module and initializing setup
from pycaret.nlp import *
nlp1 = setup(data = kiva, target = 'en')
# creating a model
lda = create_model('lda')
# plotting a model
plot_model(lda)
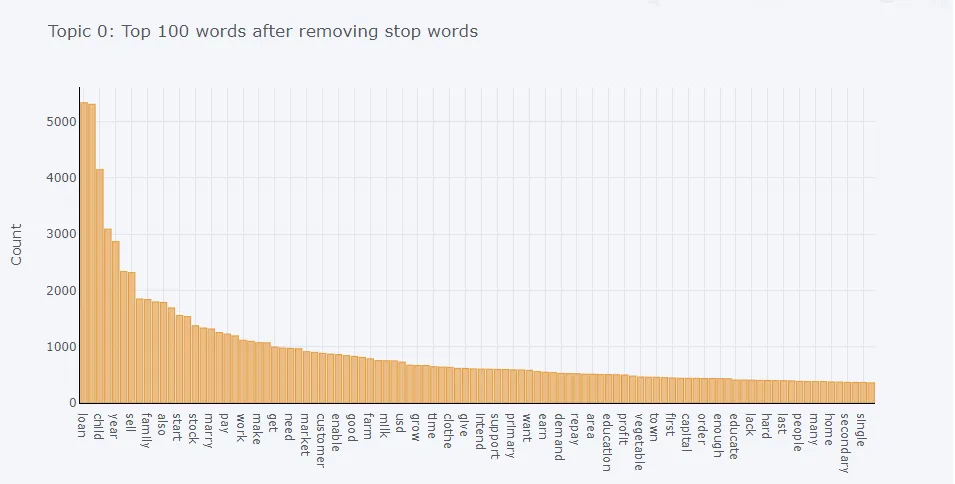

关联规则挖掘:
| Plot | Abbrev. String |
| Support, Confidence and Lift (2d) | ‘frequency’ |
| Support, Confidence and Lift (3d) | ‘distribution’ |
例子:
# Importing dataset
from pycaret.datasets import get_data
france = get_data('france')
# Importing module and initializing setup
from pycaret.arules import *
arul1 = setup(data = france, transaction_id = 'Invoice', item_id = 'Description')
# creating a model
model = create_model(metric = 'confidence')
# plotting a model
plot_model(model)

本文来自cnblogs,观点不代表一起大数据-技术文章心得立场,如若转载,请注明出处:https://www.cnblogs.com/xiximayou/p/13799181.html
更多内容请访问:IT源点
注意:本文归作者所有,未经作者允许,不得转载

